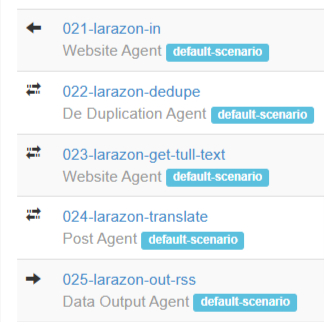
Hugin isn’t especially flexible, so I’ve basically built a chain of agents for each site. E.g., for local news site larazon.es => catalonia that neglects to keep its RSS feed updated, I do Website Agent (scrapes xpaths to get URLs), DeDupe (so I don’t translate the same articles multiple times), Website Agent again to scrape contents, title, author etc, then call Post Agent that calls OpenRouter, that uses DeepSeek v3 model (the cheapest reliable model) to translate the title and body, then make RSS.
The prompt is trivial, something like: translate to English. strip all html tags.
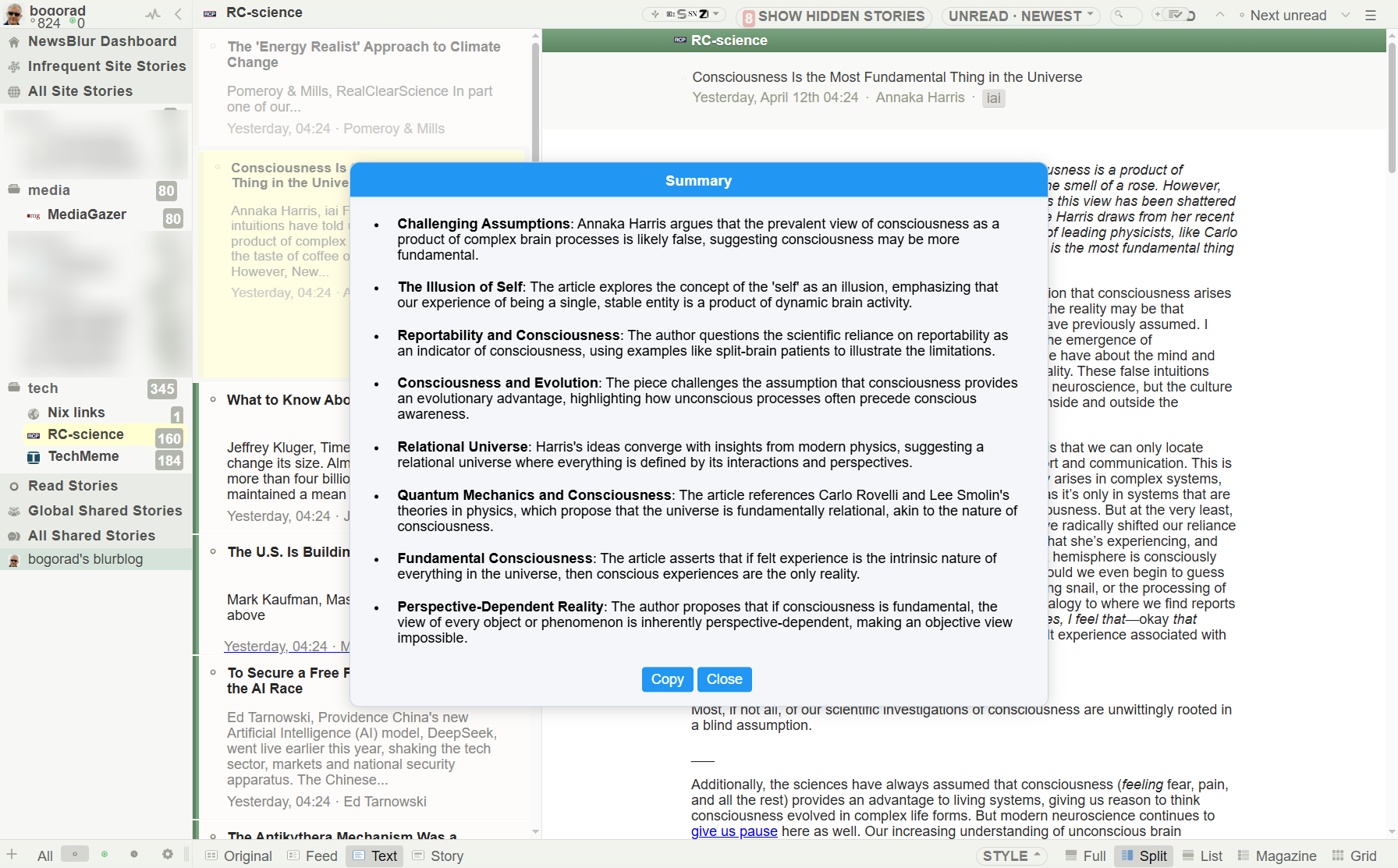
or for another site summarize in 10 bullet points. format output as html using list/ul tags
I don’t understand, what are you objecting to? The LLM feature I’m describing is basically a Web Feeds feature where we use a language model to scrape/follow a website instead of relying on a non-existent feed.
Ohh, I see above that you’re not a fan of LLM summaries, which I don’t see happening. And even if I did add that ability, it would be a separate pro feature. That’s not the kind of feature I see building for regular premium users
If you’re adding huginn (or other LLM-agent-based) monitoring of pages to generate feeds via extraction and optional translation, then presumably the “summary” capability would literally just be a case of adjusting the prompts?
In which case it could be up to the user, assuming they’re on a tier supporting custom prompts.
The only thing this single-feed approach wouldn’t automatically provide based on what we’ve been discussing would be deduplication (or grouping) of related stories which as several people have suggested is a very valuable feature.
But if you extended the pipeline to cover folders you’d get that too.
So I’ve been doing automatic summarization for most of my feeds. But it’s wasteful (I don’t mean those fractions of a cent that gemini-2-flash charges, just generally). So I came up with this chrome extension that works the following way:
while pressing ALT, you move your mouse around, and it shows you DOM objects under the cursor. when you click (or alt-click, since alt is already pressed) it extracts the highlighted DOM object and sends it to an LLM via OpenRouter.ai (my favorite LLM integrator).
The number of bullet points is configurable (3…8), it can also ask the model to translate (but not all models can/will comply). It’s a little silly extension, but it turned out to be a game-changer for me and my friends. Maybe something like that can become part of NewsBlur.
Just chiming in that I’d love (and pay a very small amount extra for) auto-translate. No particular need for summaries, just translations, even if just of their headlines, as I scroll. I have a number of Japanese-language feeds but can’t currently use them well in RSS because they’re not browsable in the blink of an eye.
Once I’ve identified an interesting story, I’m happy to click through and lean on Google auto-translate for the rest. It’s mostly just the discovery part where Newsblur would be very helpful for me.
I’d love LLM integration specifically with generating tags for stories to train on. My main frustration with NewsBlur is that most of the sites I subscribe to have limited information to go off of, usually just the title, author, and site itself (which, for blogs the last two are usually the same). I can’t always tell via keywords in the title whether or not I’d be interested in the article and even if I do, it’s often a general pattern as opposed to specific words.