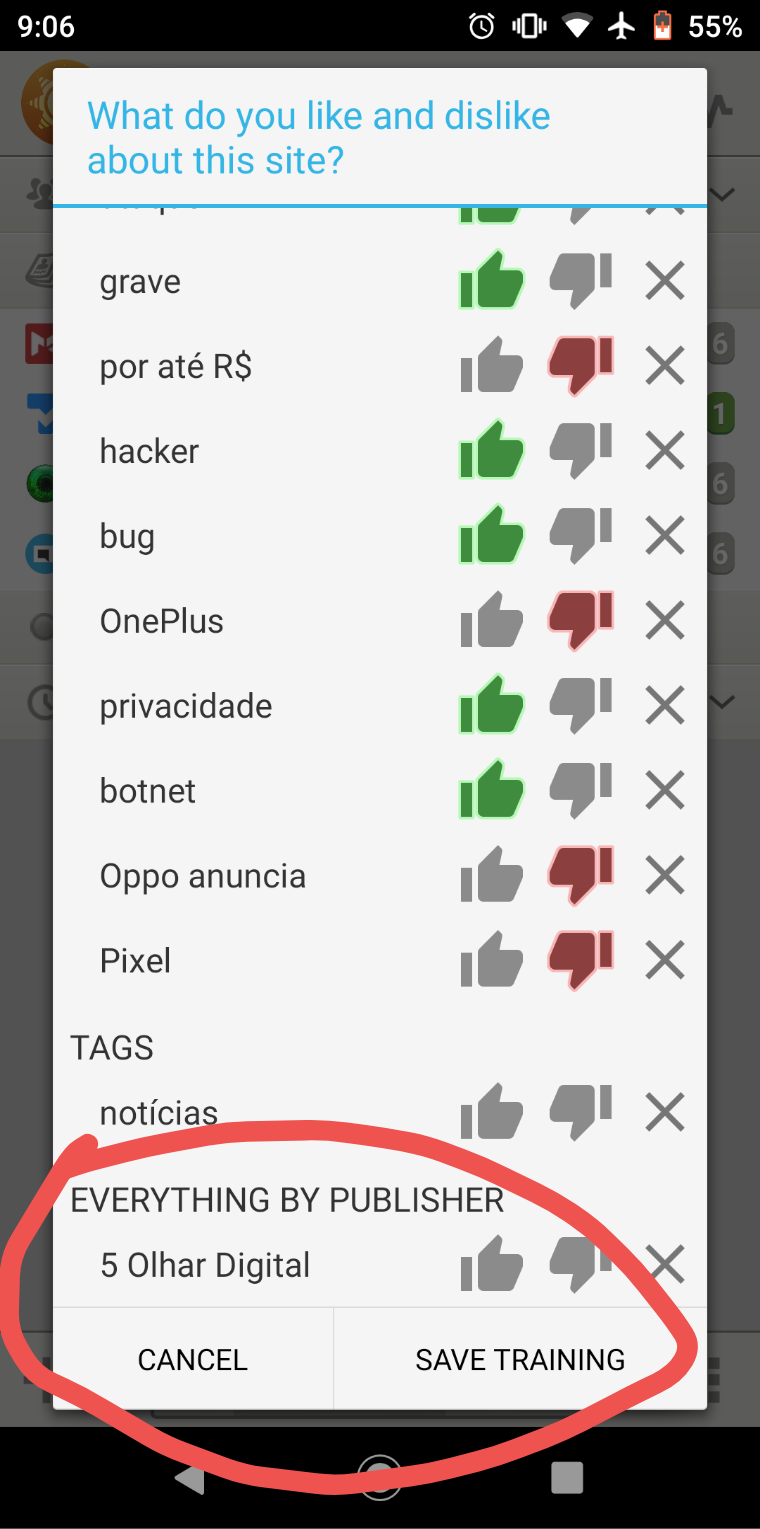
Training should detected the url and give a option for the user to like or dislike that URL,this would improve the training tool a lot!!!
For example if the user does not like any post from the url www.example.com/FOODTOPIC he could just use the training tool and unlike the whole url posts instead of needing to user the traning tool every time he sees a post talking about something about food.
This exists, just train on the publisher. Useful for feeds where you want to ignore everything except stories that have a word in the title, of which you explicitly train for.
I see,but I think that this training option is really useless now… Because all sites that I follow (when I open the trainer) the publishers that are shown are only 1 “website admin”,that’s all, so this make the whole purpose of training publishers useless in my case…
Oh, you mean the story permalink?
Now I understood what you said.
I didn’t mean that…
I’m not saying that I want to mark the whole feed as disliked and then train a few words to “liked”.
I meant to mark the whole website url (just a part of the whole website) as disliked.
So the training would “filter the word in the url” not in the article title or content…
For example,I liked a lot of things in the website, I trained a lot of words as liked or disliked but the website always post things about “food” and the url is website.com/FOOD
So instead of needing to train a lot of words related to food I would be able to put everything (all articles) that’s on the url website.com/FOOD to automatically be hidden in the newsblur feeds.
A real example is this url https://m.tecmundo.com.br/promocao
I do not want to wait my time training all words that are in the articles contained in this url. To save time I suggested that the training tool Should have an option to mark the whole url articles as hidden https://m.tecmundo.com.br/promocao
While I could use the actual an normal trainer to like or disliked words in the whole website https://m.tecmundo.com.br