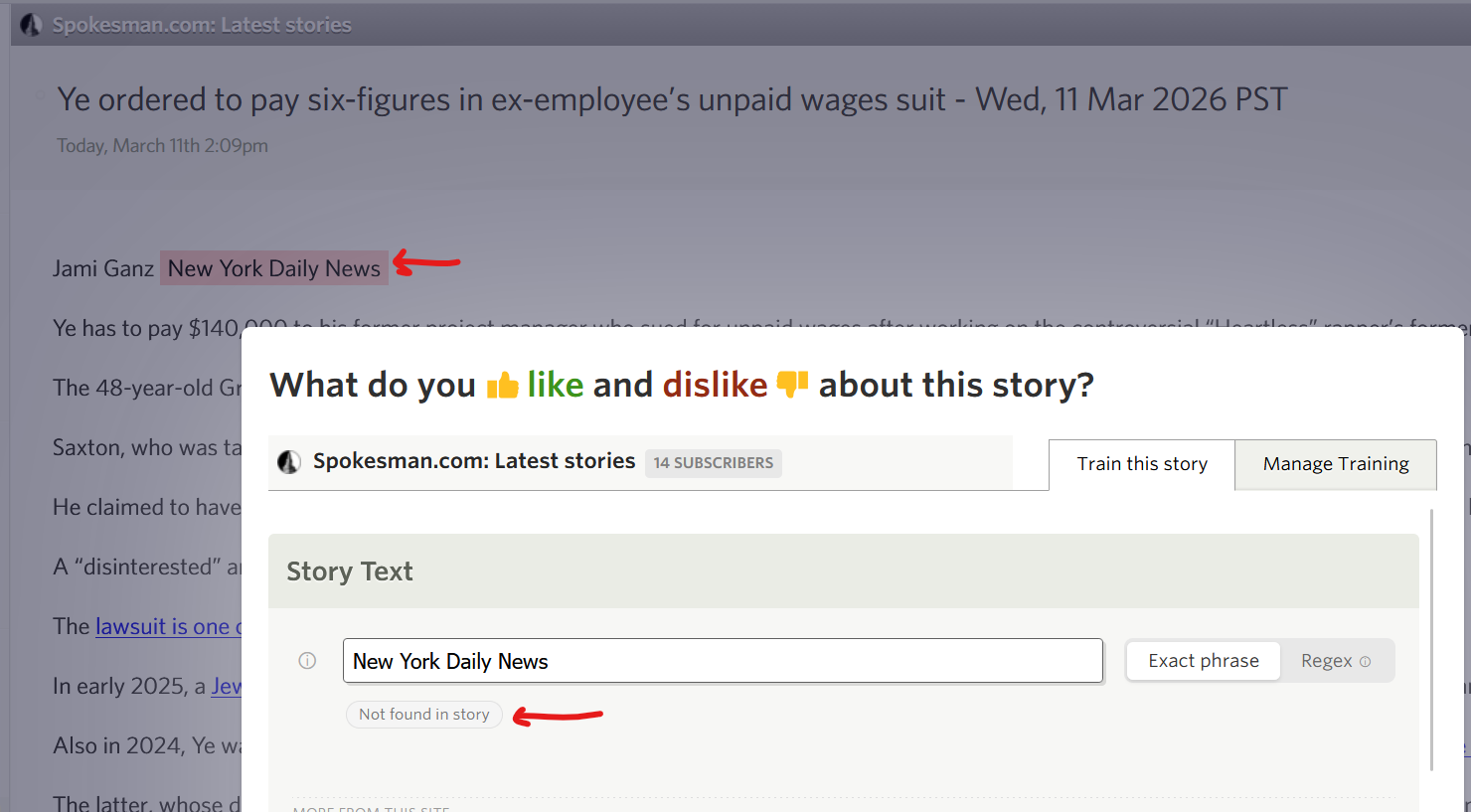
I’ve found specific sites do not seem to remove stories on trained text, for example:
domain: spokesman.com, I have trained to dislike ‘New York Daily News’, the text does highlight as disliked but the training tool shows as ‘not found in story’:
(The title based filtering however always works across all websites), I’d guesstimate less then 1 or 2% of feeds are impacted.
Thanks for reporting this! The text classifier was only checking the RSS feed body (the short summary that comes in the feed) when deciding if trained text matched. For feeds like spokesman.com that only provide short summaries, the trained text you see in the Text view wasn’t being checked for scoring or the “Found in story” indicator.
I’ve pushed a fix so that when the full article text has been fetched (via the Text view), text classifiers will also check against that content. This should fix both the scoring and the “Not found in story” message you were seeing. The fix will be deployed shortly.